
Of more than 300 billion emails sent every day, at least half are spam. Email providers have the huge task of filtering out spam and making sure their users receive the messages that matter.
Spam detection is messy. The line between spam and non-spam messages is fuzzy, and the criteria change over time. From various efforts to automate spam detection, machine learning has so far proven to be the most effective and favored approach by email providers. Although we still see spammy emails, a quick look at the junk folder will show how much spam gets weeded out of our inboxes every day thanks to machine learning algorithms.
How does machine learning determine which emails are spam and which are not? Here’s an overview of how machine learning-based spam detection works.
The challenge
Spam email comes in different flavors. Many are just annoying messages aiming to draw attention to a cause or spread false information. Some of them are phishing emails with the intent of luring the recipient into clicking on a malicious link or downloading a malware.

The
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
The one thing they have in common is that they are irrelevant to the needs of the recipient. A spam-detector algorithm must find a way to filter out spam while and at the same time avoid flagging authentic messages that users want to see in their inbox. And it must do it in a way that can match evolving trends such as panic caused from pandemics, election news, sudden interest in cryptocurrencies, and others.
Static rules can help. For instance, too many BCC recipients, very short body text, and all caps subjects are some of the hallmarks of spam emails. Likewise, some sender domains and email addresses can be associated with spam. But for the most part, spam detection mainly relies on analyzing the content of the message.
Naïve Bayes machine learning
Machine learning algorithms use statistical models to classify data. In the case of spam detection, a trained machine learning model must be able to determine whether the sequence of words found in an email are closer to those found in spam emails or safe ones.
Different machine learning algorithms can detect spam, but one that has gained appeal is the “naïve Bayes” algorithm. As the name implies, naïve Bayes is based on “Bayes’ theorem,” which describes the probability of an event based on prior knowledge.

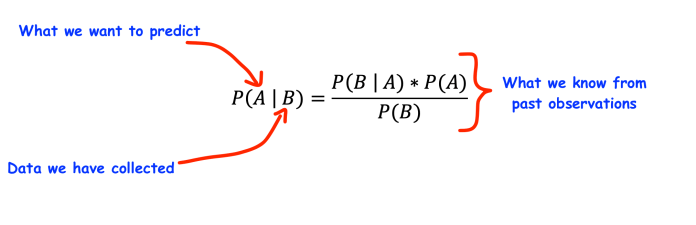
The reason it is called “naïve” is that it assumes features of observations are independent. Let’s say you want to use naïve Bayes machine learning to predict whether it will rain or not. In this case, your features could be temperature and humidity, and the event you’re predicting is rainfall.

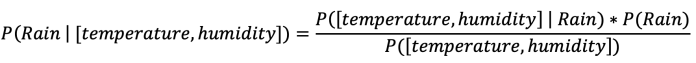
In the case of spam detection, things get a bit more complicated. Our target variable is whether a given email is “spam” or “not spam” (also called “ham”). The features are the words or word combinations found in the email’s body. In a nutshell, we want to find out calculate the probability that an email message is spam based on its text.
The catch here is that our features are not necessarily independent. For instance, consider the terms “grilled,” “cheese,” and “sandwich.” They can have separate meanings depending on whether they successively or in different parts of the message. Another example are the words “not” and “interesting.” In this case, the meaning can be completely different depending on where they appear in the message. But even though feature independence is complicated in text data, the naïve Bayes classifier has proven to be efficient in natural language processing tasks if you configure it properly.
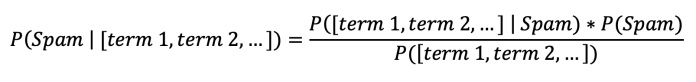
The data
Spam detection is a supervised machine learning problem. This means you must provide your machine learning model with a set of examples of spam and ham messages and let it find the relevant patterns that separate the two different categories.
Most email providers have their own vast data sets of labeled emails. For instance, every time you flag an email as spam in your Gmail account, you’re providing Google with training data for its machine learning algorithms. (Note: Google’s spam detection algorithm is much more complicated than what we’re examining here, and the company has mechanisms to prevent abuse of its “Report Spam” feature.)
There are some open-source data sets, such as the spambase data set of the University of California, Irvine, and the Enron spam data set. But these data sets are for educational and test purposes and aren’t of much use in creating production-level machine learning models.
Companies that host their own email servers can easily create specialized data sets that tune their machine learning models to the specific language of their line of work. For instance, the data set of a company that provides financial services will look much different from that of a construction company.
Training the machine learning model

Although natural language processing has seen a lot of exciting advances in recent years, artificial intelligence algorithms still don’t understand language in the way we do.
Therefore, one of the key steps in developing a spam-detector machine learning model is preparing the data for statistical processing. Before training your naïve Bayes classifier, the corpus of spam and ham emails must go through certain steps.
Consider a data set containing the following sentences:
Steve wants to buy grilled cheese sandwiches for the party
Sally is grilling some chicken for dinner
I bought some cream cheese for the cake
Text data must be “tokenized” before being fed to machine learning algorithms, both when training your models and later when making predictions on new data. In essence, tokenization means splitting your text data into smaller parts. If you split the above data set by single words (also called unigram), you’ll have the following vocabulary. Note that I’ve only included each word once.
Steve, wants, to, buy, grilled, cheese, sandwiches, for, the, party, Sally, is, grilling, some, chicken, dinner, I, bought, cream, cake
We can remove words that appear both in spam and ham emails and don’t help in telling the difference between the two classes. These are called “stop words” and include terms such as the, for, is, to, and some. In the above data set, removing stop words will reduce the size of our vocabulary by five words.
We can also use other techniques such as “stemming” and “lemmatization,” which transform words to their base forms. For instance, in our example data set, buy and bought have a common root, as do grilled and grill. Stemming and lemmatization can help further simplify our machine learning model.
In some cases, you should consider using bigrams (two-word tokens), trigrams (three-word token), or larger n-grams. For instance, tokenizing the above data set in bigram form will give us terms such as “cheese cake,” and using trigrams will produce “grilled cheese sandwich.”
Once you’ve processed your data, you’ll have a list of terms that define the features of your machine learning model. Now you must determine which words or—if you’re using n-grams—word sequences are relevant to each of your spam and ham classes.
When you train your machine learning model on the training data set, each term is assigned a weight based on how many times it appears in spam and ham emails. For instance, if “win big money prize” is one of your features and only appears in spam emails, then it will be given a larger probability of being spam. If “important meeting” is only mentioned in ham emails, then its inclusion in an email will increase the probability of that email being classified as not spam.
Once you have processed the data and assigned the weights to the features, your machine learning model is ready filter spam. When a new email comes in, the text is tokenized and run against the Bayes formula. Each term in the message body is multiplied by its weight and the sum of the weight determine the probability that the email is spam. (In reality, the calculation is a bit more complicated, but to keep things simple, we’ll stick to the sum of weights.)
Advanced spam detection with machine learning

Simple as it sounds, the naïve Bayes machine learning algorithm has proven to be effective for many text classification tasks, including spam detection.
But this does not mean that it is perfect.
Like other machine learning algorithms, naïve Bayes does not understand the context of language and relies on statistical relations between words to determine whether a piece of text belongs to a certain class. This means that, for instance, a naïve Bayes spam detector can be fooled into overlooking a spam email if the sender just adds some non-spam words at the end of the message or replace spammy terms with other closely related words.
Naïve Bayes is not the only machine learning algorithm that can detect spam. Other popular algorithms include recurrent neural networks (RNN) and transformers, which are efficient at processing sequential data like email and text messages.
A final thing to note is that spam detection is always a work in progress. As developers use AI and other technology to detect and filter out noisome messages from emails, spammers find new ways to game the system and get their junk past the filters. That is why email providers always rely on the help of users to improve and update their spam detectors.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here. [LINK]
Get the TNW newsletter
Get the most important tech news in your inbox each week.